Docs / Core Concepts
Core Concepts
Evaligo organizes AI evaluation around five core concepts that work together to provide comprehensive quality assurance from development through production deployment.
Understanding these building blocks and their relationships is essential for effectively using Evaligo to improve your AI applications. Each concept serves a specific role in the evaluation workflow, from organizing your work to measuring quality and monitoring production performance.
This conceptual foundation applies whether you're evaluating chatbots, content generation systems, code assistants, or any other AI application. The same principles scale from single-person projects to enterprise-wide AI governance.
The Evaluation Hierarchy
Evaligo's architecture follows a logical hierarchy that mirrors how teams actually work with AI systems. At the top level, projects organize everything around a specific AI application or use case.
Projects: Your AI Application Workspace
A project represents a single AI application or feature you're developing and evaluating. Think of it as a dedicated workspace that contains all the datasets, experiments, evaluations, and production traces related to that specific use case.
Projects provide isolation between different AI initiatives while enabling team collaboration within each application scope. For example, you might have separate projects for "Customer Support Chatbot", "Code Review Assistant", and "Content Generation API".
Within each project, you'll track performance over time, compare different approaches, and maintain a history of what works best for your specific domain and requirements.
Datasets: Representative Test Cases
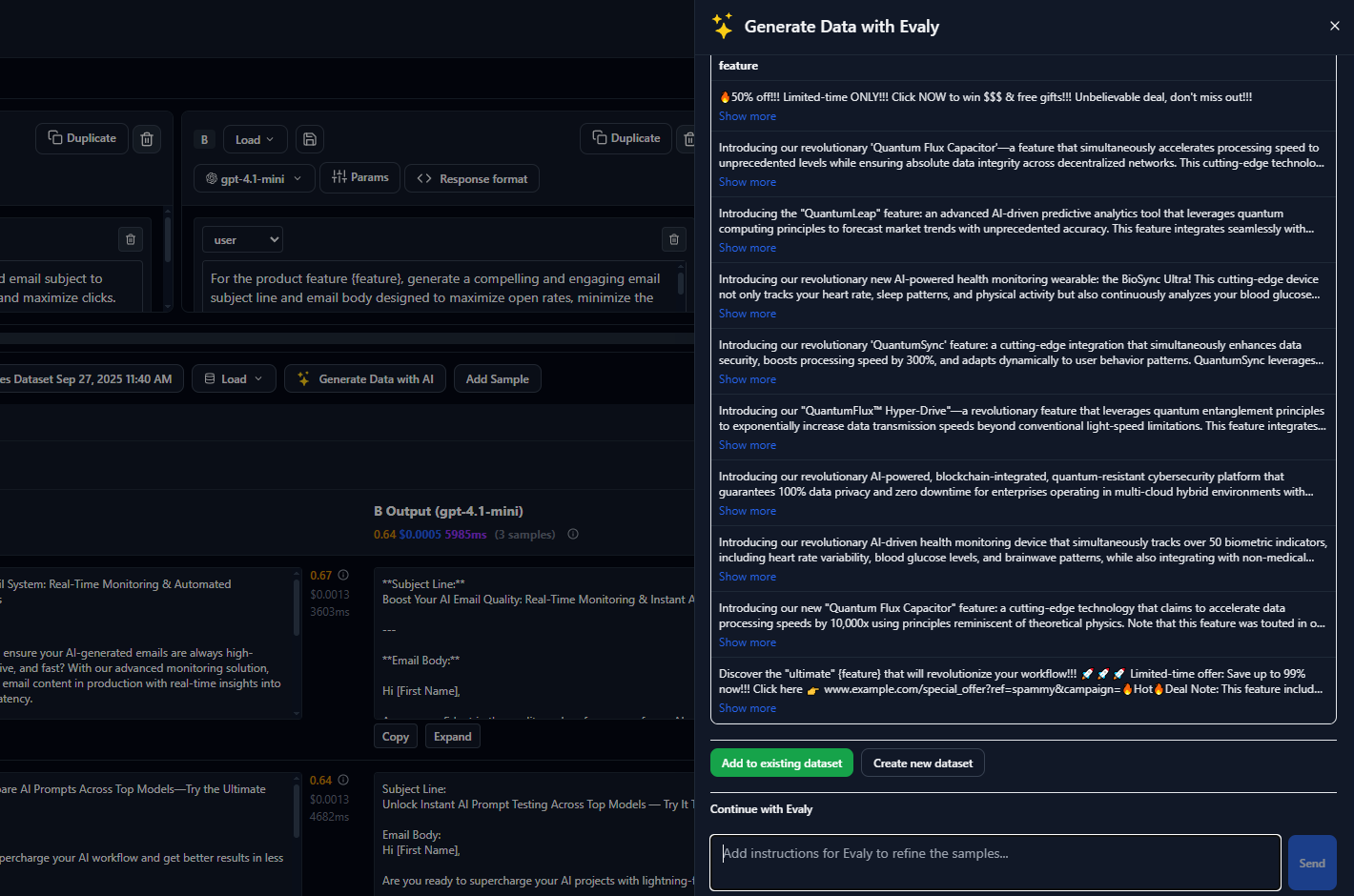
Datasets are collections of inputs and expected outputs that represent real-world scenarios your AI system will encounter. They serve as the foundation for objective evaluation by providing consistent test cases across all experiments.
High-quality datasets should cover edge cases, typical inputs, and challenging scenarios that reveal model limitations. Include both positive examples (where you expect good performance) and negative examples (where the AI should refuse or handle gracefully).
Datasets evolve over time as you discover new edge cases, update requirements, or expand into new use cases. Evaligo tracks dataset versions so you can compare performance across different test case collections.
Most teams start with 20-50 curated test cases and gradually expand to hundreds or thousands as they move toward production deployment.
Generate Diverse Test Data
Dataset Quality Metrics
Experiments: Systematic Comparison
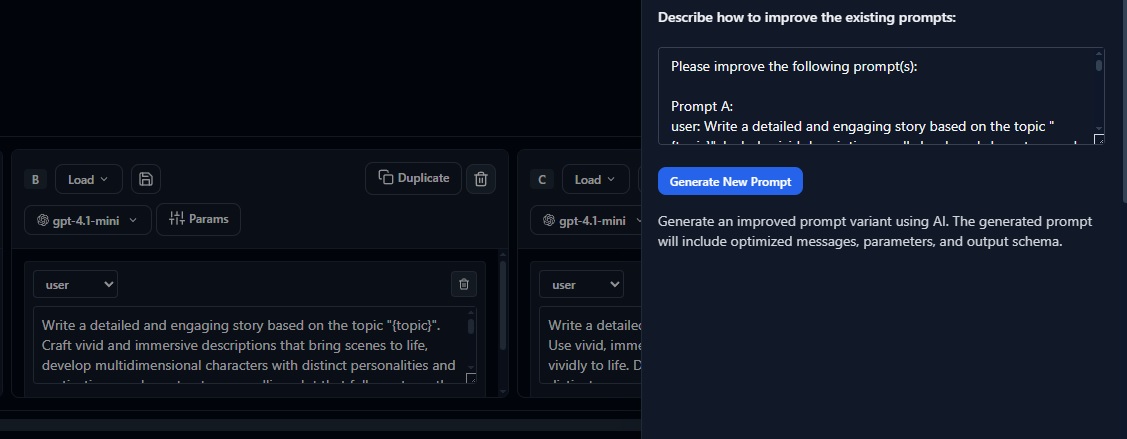
Experiments run multiple prompt or model variants against your datasets to enable objective comparison. Instead of manually testing different approaches, experiments automate this process and provide structured results.
Each experiment tests specific hypotheses about what might improve performance. For example, "Does adding examples improve accuracy?" or "Is GPT-4 worth the extra cost for this use case?" Experiments provide data-driven answers.
Experiments capture not just response quality but also performance metrics like latency, token usage, cost per request, and error rates. This holistic view helps you optimize for multiple objectives simultaneously.
The experimental approach encourages disciplined iteration. Rather than tweaking prompts based on gut feeling, you test changes systematically and measure their impact across your entire dataset.
Evaluations: Objective Quality Measurement
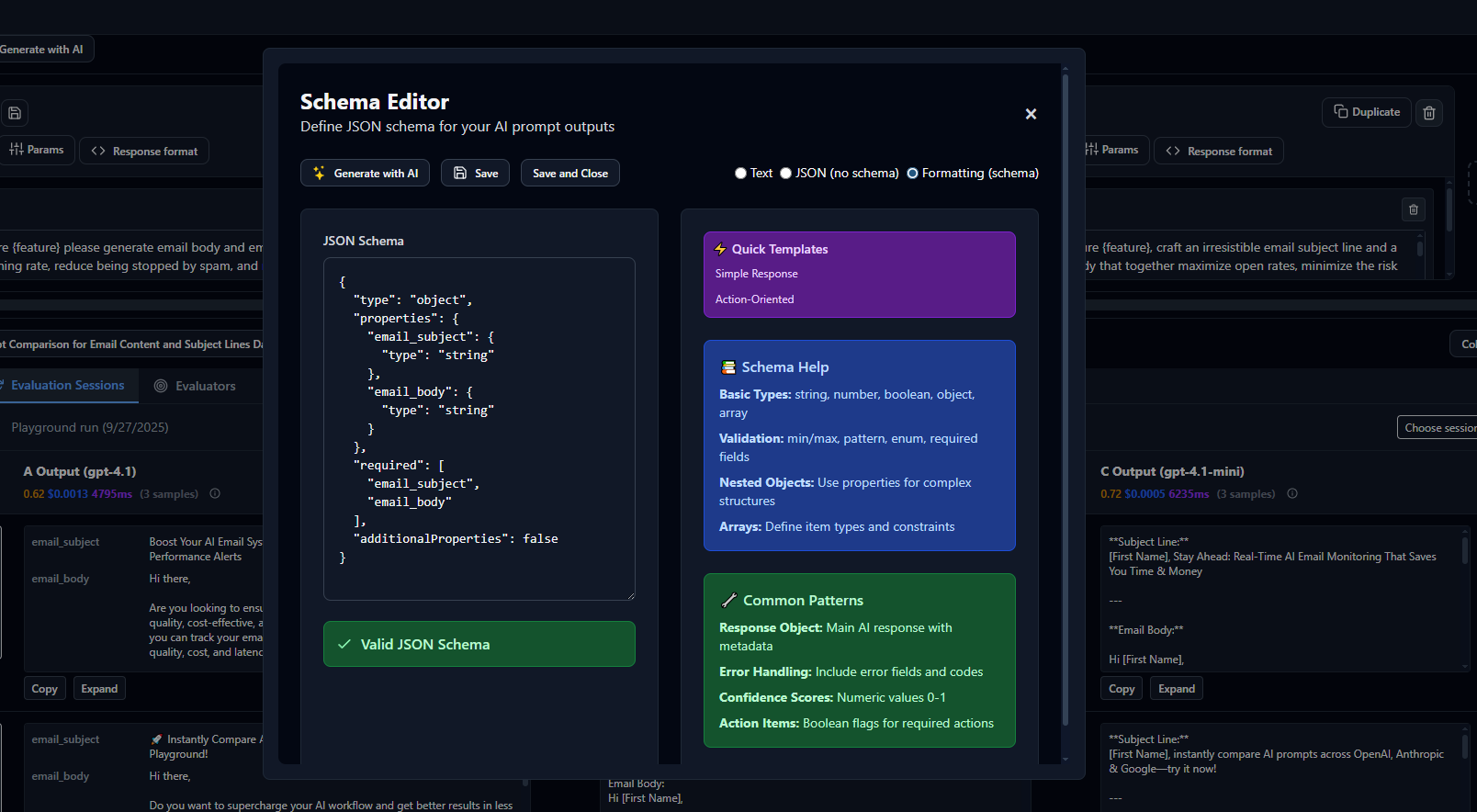
Evaluations automatically score AI responses across multiple dimensions like accuracy, helpfulness, safety, and domain-specific criteria. They replace subjective human review with consistent, repeatable assessment.
Evaligo provides built-in evaluators for common objectives (factual accuracy, toxicity detection, instruction following) and supports custom evaluators for domain-specific requirements. You can combine multiple evaluation criteria to get a comprehensive quality picture.
Evaluations use various approaches including LLM-based judges, rule-based checks, similarity scoring, and integration with human annotation workflows. The right combination depends on your specific quality requirements and constraints.
Consistent evaluation enables tracking improvement over time, comparing different teams' approaches, and setting quality gates for production deployment.
Evaluation Results Dashboard

Custom Evaluator Configuration

AI-Powered Schema Editor
Tracing: Production Monitoring
Tracing captures real-world usage of your AI application in production, closing the feedback loop between development evaluation and live performance. It's essential for catching issues that don't appear in controlled testing.
Production traces include user inputs, AI responses, performance metrics, error rates, and any feedback signals available from real users. This data reveals how well your laboratory evaluation translates to real-world usage.
Tracing enables continuous monitoring of quality degradation, cost spikes, latency issues, and emerging edge cases that weren't covered in your original datasets.
The most sophisticated teams use production insights to automatically update their evaluation datasets, ensuring their testing remains representative of actual usage patterns.
Video
How the Concepts Work Together
These concepts form an integrated workflow that supports the complete AI development lifecycle. Projects organize your work, datasets define your quality standards, experiments drive systematic improvement, evaluations provide objective measurement, and tracing ensures production success.
The workflow typically progresses from initial dataset creation through iterative experimentation, rigorous evaluation, and finally production deployment with ongoing monitoring. Each stage builds on the previous one while feeding insights back into the cycle.
- 1
Define Success Criteria Create datasets that represent your quality standards and real-world usage patterns.
- 2
Iterate Systematically Run experiments to test hypotheses about what improves performance.
- 3
Measure Objectively Use evaluations to score quality across multiple dimensions consistently.
- 4
Deploy with Confidence Monitor production performance and catch regressions early.
- 5
Continuous Improvement Use production insights to improve datasets and evaluation criteria.
Best Practices and Naming Conventions
Consistent naming and organization become crucial as your evaluation workflows grow. Establish conventions early to make collaboration easier and results more discoverable.
Project Naming
Include the application type, team, and optionally the time period or version. Examples: "ChatBot-Support-2024", "CodeReview-DevTools-v2", "ContentGen-Marketing-Q1".
Dataset Naming
Describe the content, source, and date. Examples: "customer-inquiries-jan2024", "code-review-comments-production", "marketing-copy-requests-validated".
Experiment Naming
Indicate what you're testing and the variant. Examples: "baseline-vs-examples", "gpt4-vs-claude-cost-comparison", "temperature-optimization-v3".
Next Steps
Now that you understand Evaligo's core concepts, you're ready to start building your first evaluation workflow. The quickstart guide provides hands-on experience with each concept.