Docs / LLM as a Judge
LLM as a Judge
LLM-as-a-Judge transforms AI evaluation by providing sophisticated, human-like assessment that scales to thousands of evaluations. While traditional metrics capture basic quality, LLM judges can assess nuanced qualities like helpfulness, creativity, and appropriateness.
This approach bridges the gap between simple rule-based evaluation and expensive human annotation. LLM judges provide consistent, explainable assessments that can evaluate subjective qualities at scale while maintaining transparency through detailed explanations.
As language models become more capable and cost-effective, LLM-based evaluation has become a cornerstone of modern AI quality assurance, enabling rapid iteration and comprehensive quality assessment that would be impossible with human evaluation alone.
Whether you're evaluating creative content, assessing conversational quality, or measuring domain-specific expertise, LLM judges provide the sophisticated assessment capabilities that modern AI applications require.
Why LLM Judges Excel
LLM judges combine the nuanced understanding of human evaluators with the consistency and scale of automated systems. They can understand context, assess subjective qualities, and provide detailed explanations for their decisions.
Unlike rule-based evaluators that check for specific patterns, LLM judges can make holistic assessments that consider multiple factors simultaneously, much like human evaluators but with perfect consistency and unlimited availability.
Core Components of LLM Evaluation
Effective LLM-based evaluation requires careful design of the evaluation prompt, clear scoring criteria, and structured output formats that ensure consistent and interpretable results.
- 1
Evaluation Prompt Clear instructions that define what quality means and how to assess it consistently.
- 2
Scoring Rubric Detailed criteria that specify what constitutes different quality levels with examples.
- 3
Input Context All relevant information the judge needs including inputs, outputs, and reference materials.
- 4
Structured Output Consistent format for scores, reasoning, and recommendations that enables analysis.
Designing Effective Judge Prompts
The evaluation prompt is the most critical component of LLM-based evaluation. It must clearly communicate evaluation criteria, provide sufficient context, and elicit consistent, well-reasoned judgments.
Effective judge prompts include clear instructions, specific criteria, concrete examples, and structured output formats. They balance specificity (to ensure consistency) with flexibility (to handle diverse inputs).
// Example LLM judge prompt for customer service evaluation
TASK: Evaluate the quality of a customer service response.
CRITERIA:
1. HELPFULNESS (1-5): Does the response directly address the customer's question and provide actionable guidance?
- 5: Completely addresses the question with clear, actionable steps
- 4: Mostly addresses the question with good guidance
- 3: Partially addresses the question with some useful information
- 2: Minimally addresses the question with limited usefulness
- 1: Fails to address the question or provides unhelpful information
2. EMPATHY (1-5): Does the response show understanding and care for the customer's situation?
- 5: Shows genuine understanding and acknowledges customer emotions
- 4: Shows good understanding with appropriate tone
- 3: Shows basic understanding with neutral tone
- 2: Shows limited understanding with slightly cold tone
- 1: Shows no understanding or empathy
3. CLARITY (1-5): Is the response easy to understand and well-organized?
- 5: Crystal clear with perfect organization and language
- 4: Very clear with good organization
- 3: Generally clear with adequate organization
- 2: Somewhat unclear or poorly organized
- 1: Confusing or very poorly organized
INPUT:
Customer Question: {input}
AI Response: {output}
INSTRUCTIONS:
1. Read the customer question carefully to understand their need
2. Evaluate the AI response using the criteria above
3. Provide specific evidence from the response to justify each score
4. Calculate an overall quality score as the average of all criteria
OUTPUT FORMAT:
{
"helpfulness": {
"score": [1-5],
"reasoning": "[Specific evidence and justification]"
},
"empathy": {
"score": [1-5],
"reasoning": "[Specific evidence and justification]"
},
"clarity": {
"score": [1-5],
"reasoning": "[Specific evidence and justification]"
},
"overall_score": [1-5],
"summary": "[Brief overall assessment]",
"recommendations": "[Specific suggestions for improvement]"
}Configuring Evaluators in the UI
The evaluator editor provides a visual interface for configuring LLM judges with all the components needed for effective evaluation. You can customize the evaluation prompt, define scoring criteria, specify input variables, and configure how context and data samples are provided to the judge.
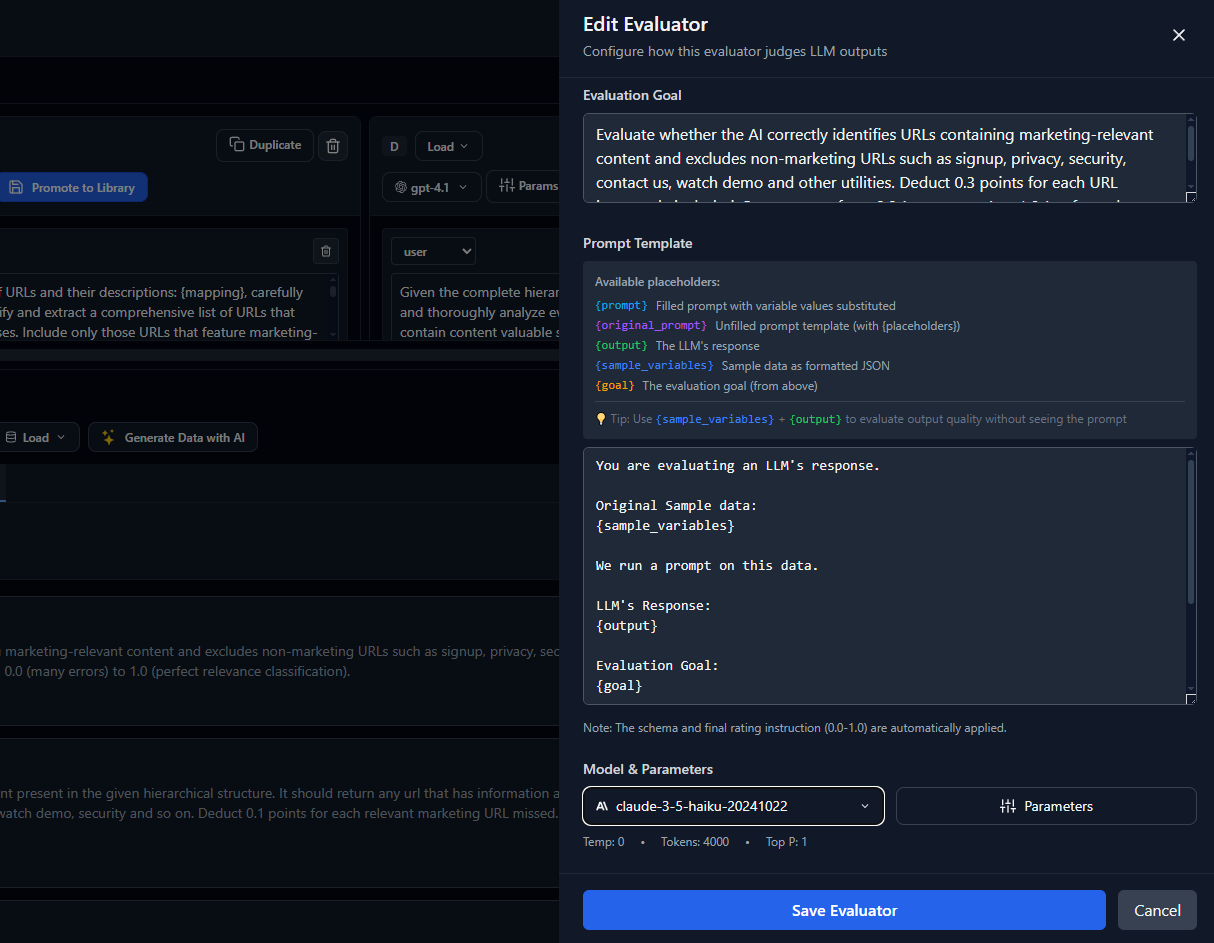
The evaluator configuration includes several key fields that work together to create comprehensive judgments:
- 1
Context Background information and guidelines that help the judge understand what quality means for your specific use case.
- 2
Input Variables The data being evaluated, such as user queries, prompts, or reference materials that the judge needs to assess.
- 3
Data Sample Test examples that demonstrate the expected input/output format and help validate judge behavior.
- 4
Judge Prompt The evaluation instructions that define criteria, scoring scales, and output format for consistent assessment.
- 5
Output Format Structured format specification ensuring the judge returns scores, reasoning, and recommendations in a parseable format.
This visual editor makes it easy to iterate on your evaluation criteria without writing code. You can test changes immediately, compare different judge configurations, and ensure your evaluators align with your quality standards before deploying them in experiments or production monitoring.
Multiple Evaluators in the Playground
In practice, you'll often configure multiple evaluators to assess different quality dimensions of your AI outputs. The playground allows you to run several evaluators simultaneously, giving you comprehensive feedback across all the criteria that matter for your use case.
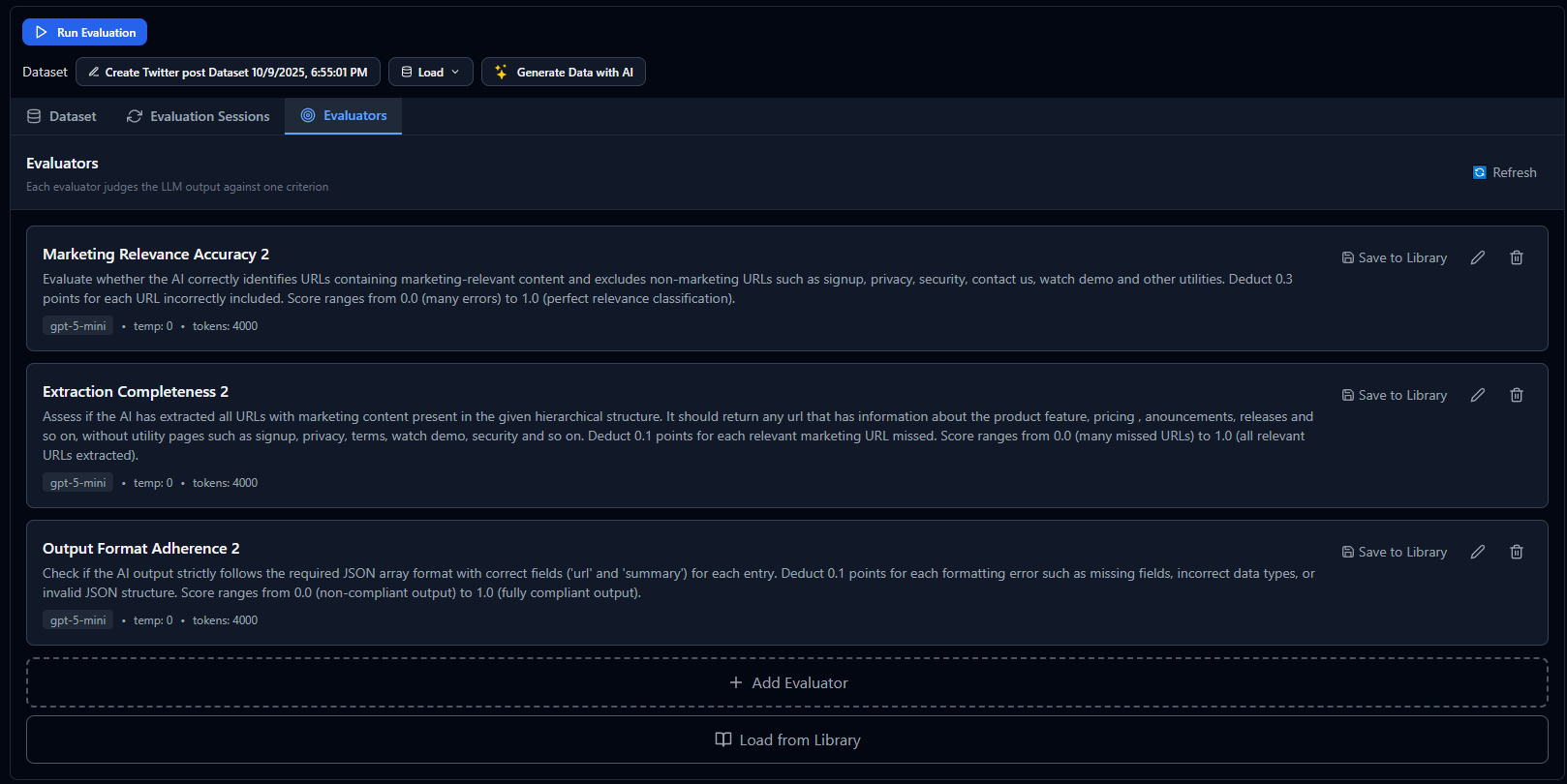
By combining multiple evaluators, you can create a holistic quality assessment framework that evaluates your prompts from multiple angles. This multi-evaluator approach provides richer insights than any single metric could offer, helping you identify strengths and weaknesses across different quality dimensions.
Multi-Dimensional Evaluation
LLM judges excel at assessing multiple quality dimensions simultaneously, providing comprehensive evaluation that captures different aspects of response quality in a single evaluation.
Structure your evaluation to assess 3-5 key dimensions that matter most for your application. More dimensions provide richer feedback but may reduce consistency, so balance comprehensiveness with reliability.
Common Evaluation Dimensions
Different applications benefit from different evaluation dimensions based on their specific quality requirements and user expectations.
Content Quality
Accuracy, completeness, relevance, depth, and factual correctness of the response content.
Communication Style
Clarity, tone, professionalism, empathy, and appropriateness of the communication style.
Task Performance
Instruction following, problem-solving effectiveness, goal achievement, and user need satisfaction.
Safety and Appropriateness
Harmlessness, bias detection, content safety, and alignment with values and guidelines.
Judge Model Selection and Configuration
Different LLMs have different strengths as judges. More capable models generally provide better evaluation quality but at higher cost. Choose based on your accuracy requirements and budget constraints.
Configure judge models with low temperature for consistency, appropriate context windows for complex evaluations, and structured output modes when available to ensure reliable formatting.
Model Comparison for Evaluation
Consider these factors when selecting judge models for your evaluation needs.
GPT-4 and GPT-4 Turbo
Excellent evaluation quality with strong reasoning and consistency. Higher cost but provides detailed, reliable assessments for complex criteria.
Claude (Anthropic)
Strong performance on safety and appropriateness evaluation. Good balance of quality and cost with particular strength in nuanced judgment.
Open Source Models
Cost-effective options for simpler evaluation tasks. May require more prompt engineering but offer full control and lower operating costs.
// Judge model configuration example
{
"judge_config": {
"model": "gpt-4",
"temperature": 0.1, // Low temperature for consistency
"max_tokens": 1000, // Enough for detailed reasoning
"response_format": "json_object", // Structured output
"system_prompt": "You are an expert evaluator trained to assess AI responses objectively and consistently."
},
"evaluation_settings": {
"retry_on_format_error": true,
"validation_schema": "customer_service_rubric_v2",
"cost_limit_per_eval": 0.05,
"timeout_seconds": 30
}
}Calibration and Validation
Calibrate your LLM judges against human evaluators to ensure they're assessing quality according to your standards. Regular validation maintains evaluation quality as models and requirements evolve.
Create golden datasets with human-annotated examples that represent the range of quality you expect to see. Use these to validate judge performance and tune evaluation prompts.
Video
Calibration Process
Follow a systematic approach to align LLM judge behavior with human expectations and organizational standards.
Human Annotation
Have experts evaluate 50-100 representative examples using your criteria to establish ground truth standards.
Judge Evaluation
Run your LLM judge on the same examples and compare results to identify systematic differences or biases.
Prompt Refinement
Adjust evaluation prompts, criteria, or examples based on discrepancies to improve alignment with human judgment.
Ongoing Monitoring
Regularly spot-check judge evaluations against human assessment to detect drift or changing requirements.
Handling Edge Cases and Bias
LLM judges can exhibit biases or struggle with edge cases just like human evaluators. Design evaluation processes that identify and mitigate these issues systematically.
Common challenges include length bias (preferring longer responses), style bias (favoring certain writing styles), and inconsistency across similar examples. Address these through careful prompt design and validation.
Bias Mitigation Strategies
Implement systematic approaches to identify and reduce evaluation bias in your LLM judges.
Blind Evaluation
Remove identifying information that might bias judgment, such as model names, response metadata, or ordering effects.
Multiple Judges
Use multiple judge models or prompt variations to identify inconsistencies and improve reliability through consensus.
Systematic Testing
Test judge behavior on edge cases, controversial topics, and adversarial examples to identify failure modes.
Integration and Automation
Integrate LLM judges into your evaluation workflows to provide continuous quality assessment throughout development and production. Automation enables consistent quality gates without manual bottlenecks.
Set up automatic evaluation on experiment completion, periodic production quality checks, and alert systems for quality degradation to maintain high standards continuously.
Workflow Integration
LLM judges work best when integrated into existing development and deployment workflows rather than as standalone evaluation steps.
Experiment Integration
Automatically evaluate all experiment variants with LLM judges to provide comprehensive quality comparison alongside traditional metrics.
CI/CD Integration
Use LLM judges as quality gates in deployment pipelines to prevent low-quality changes from reaching production.
Production Monitoring
Continuously evaluate production outputs to detect quality degradation and emerging issues before they impact users.
Cost Optimization
LLM-based evaluation can become expensive at scale. Implement cost optimization strategies that maintain evaluation quality while controlling expenses.
Use sampling for routine evaluation, reserve comprehensive assessment for critical decisions, and optimize prompt efficiency to reduce token usage without sacrificing quality.
Cost Management Strategies
Balance evaluation coverage with cost constraints through strategic choices about when and how to use LLM judges.
Intelligent Sampling
Evaluate representative samples rather than entire datasets for routine quality monitoring, with full evaluation for critical releases.
Model Selection
Use less expensive models for simpler evaluation tasks and reserve premium models for complex, nuanced assessment.
Prompt Optimization
Design efficient prompts that provide necessary context without excessive token usage, and use batch evaluation when possible.
Next Steps
With LLM judges in your evaluation toolkit, you can assess sophisticated qualities that traditional metrics miss, enabling comprehensive quality assurance that scales with your AI applications.