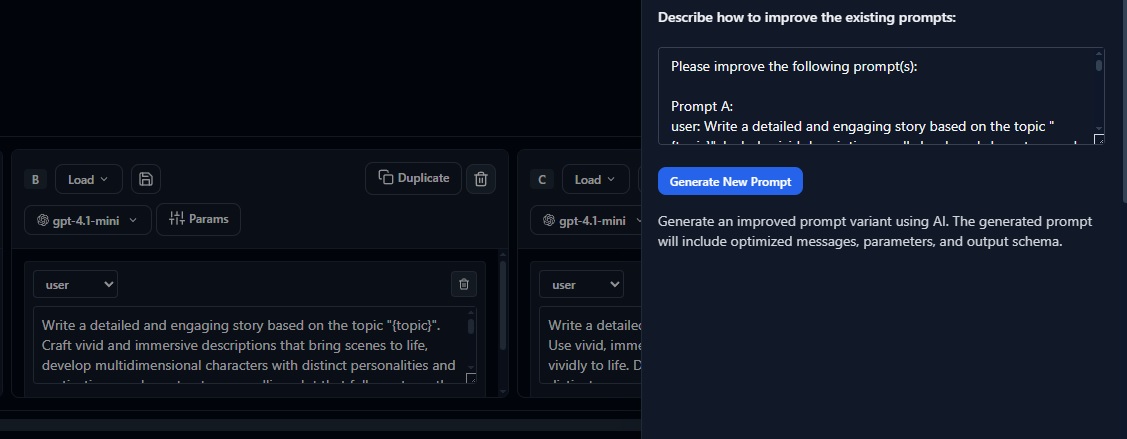
Execute comprehensive evaluations directly in your browser with an intuitive interface that makes quality assessment accessible to both technical and non-technical team members. Set up evaluators, run assessments, and analyze results without writing code.
The UI-based evaluation workflow is designed for rapid iteration and collaborative review. Product managers, domain experts, and QA teams can contribute to the evaluation process without needing to write code or understand technical implementation details.
This approach enables faster feedback loops and more inclusive quality assessment processes. Teams can quickly validate changes, explore different evaluation criteria, and build consensus around quality standards through shared analysis sessions.
Setting Up Evaluations
Configure evaluations through guided workflows that walk you through dataset selection, evaluator configuration, and run parameters. The interface provides smart defaults while allowing customization for specific requirements.
- 1
Select your dataset Choose from existing datasets or upload new test data directly through the interface.
- 2
Configure evaluators Select from built-in templates or configure custom evaluators with adjustable parameters and thresholds.
- 3
Set run parameters Define sampling strategy, parallel execution settings, and notification preferences for the evaluation run.
- 4
Review and start Preview the configuration and start the evaluation with real-time progress monitoring.
Smart Defaults: The interface automatically suggests relevant evaluators based on your dataset type and historical usage patterns, accelerating setup for common scenarios.
Video
Built-in Evaluator Templates
Leverage pre-configured evaluators for common quality dimensions like groundedness, toxicity, relevance, and coherence. These templates are based on industry best practices and can be customized to match your specific requirements.
Template evaluators provide immediate value without requiring domain expertise in evaluation design. They come with sensible defaults, clear documentation, and proven effectiveness across diverse use cases.
- 1
Safety evaluators Detect harmful content, toxicity, bias, and inappropriate responses with configurable sensitivity levels.
- 2
Accuracy evaluators Assess factual correctness, groundedness, and alignment with reference materials using various comparison methods.
- 3
Style evaluators Evaluate tone, formality, clarity, and adherence to brand voice guidelines.
- 4
Performance evaluators Monitor response time, token usage, and cost efficiency across different model configurations.
Template Customization: All templates can be adjusted for threshold sensitivity, scoring weights, and evaluation criteria to match your specific quality requirements and risk tolerance.
{
"evaluator": "groundedness_template",
"version": "2.1.0",
"parameters": {
"threshold": 0.8,
"evidence_requirement": "strict",
"citation_format": "required",
"hallucination_detection": {
"enabled": true,
"sensitivity": "medium",
"categories": ["factual", "temporal", "numerical"]
}
},
"scoring": {
"scale": "0-1",
"weights": {
"factual_accuracy": 0.4,
"source_alignment": 0.3,
"citation_quality": 0.3
}
},
"output_format": {
"include_explanations": true,
"highlight_issues": true,
"confidence_scores": true
}
}Real-time Monitoring
Track evaluation progress with live updates showing completion status, preliminary results, and any issues that arise during execution. The interface provides transparency into the evaluation process and enables early intervention if needed.
Real-time monitoring helps teams understand evaluation performance and identify potential issues before they impact results. Progress indicators show not just completion percentage but also quality trends and resource utilization.
Large Dataset Handling: For datasets with thousands of rows, the interface provides sampling options and batch processing to manage evaluation time and costs effectively.
Results Analysis and Visualization
Explore evaluation results through interactive dashboards that highlight key insights, problematic cases, and performance trends. The interface makes it easy to drill down from aggregate metrics to individual examples.
Visual analysis tools help teams quickly identify patterns in model performance and prioritize areas for improvement. Interactive charts and filtering capabilities enable deep exploration without requiring data analysis expertise.
- 1
Aggregate dashboard Overview of key metrics, score distributions, and comparison with baseline performance.
- 2
Failure analysis Detailed view of low-scoring cases with explanations and suggested improvements.
- 3
Trend analysis Performance patterns across different input types, time periods, or model variants.
- 4
Export capabilities Download results in multiple formats for further analysis or stakeholder reporting.
Video
Collaborative Review
Share evaluation results with team members and stakeholders through built-in collaboration features. Comment on specific results, tag team members for review, and maintain discussion threads around quality decisions.
// Generate shareable evaluation report
const report = await evaluation.generateReport({
includeRawData: false,
highlightThreshold: 0.7,
maxExamples: 20,
sections: [
'executive_summary',
'key_findings',
'recommendations',
'sample_outputs'
]
});
// Share with stakeholders
await report.shareWith({
emails: ['product@company.com', 'qa@company.com'],
permissions: ['view', 'comment'],
expirationDays: 30,
message: 'Review of customer support model v2.1 evaluation results'
});
// Set up automated notifications for score thresholds
await evaluation.configureAlerts({
lowScoreThreshold: 0.75,
recipients: ['ai-team@company.com'],
includeExamples: true,
escalationRules: {
criticalIssues: 'immediate',
performanceDegradation: 'daily_digest'
}
});Preset Management
Save successful evaluator configurations as reusable presets for consistent assessment across different projects and team members. Presets capture not just the technical configuration but also the reasoning and context behind evaluation choices.
Preset Organization: Organize presets by use case, quality level, or team to make them easily discoverable. Include clear documentation about when and how to use each preset.